Recently, I started looking at Kubernetes. As a first step, I went through the tutorial on how to install Minikube. On this link, we get the instructions on how to set up Minikube on Windows 10 using either Hyper-V or VirtualBox as a hypervisor. However, my preference is to use VMware Workstation as the hypervisor. When I went through their tutorial, I found that the documentation for setting this up was not available on the MiniKube vmware driver page at the time of writing. After troubleshooting, I installed Minikube and managed to get it working with VMware Workstation. Here are the steps that I followed.
Install a Hypervisor
- Install VMware Workstation 15.5.
- After installing VMware Workstation, we need to have vmrun.exe on your Windows PATH. Add C:\Program Files (x86)\VMware\VMware Workstation to your Windows PATH variable.
- As an example of how to do this, I referred to the link at Add a folder to your Windows PATH variable.
Install Docker machine driver
- Download Docker machine driver docker-machine-driver-vmware_windows_amd64.exe from https://github.com/machine-drivers/docker-machine-driver-vmware/releases.
- Create a folder at C:\Program Files\docker-machine-driver.
- Copy docker-machine-driver-vmware_windows_amd64.exe to this folder.
- Rename docker-machine-driver-vmware_windows_amd64.exe to docker-machine-driver-vmware.exe.
- Add this folder to your Windows PATH variable as above.
Install kubectl
- These steps are distilled from the instructions at Install and Set Up kubectl.
- Download the latest version of kubectl for Windows/AMD64.
- Create a folder at C:\Program Files\Kubectl.
- Add the kubectl.exe to this folder.
- Add this folder to your Windows PATH variable.
Check the version
kubectl version --client
Install Minikube using an installer executable
These instructions are distilled from the MiniKube documentation. Please note that I specify the hypervisor driver as vmware. To install Minikube manually on Windows using the Windows Installer for AMD64, download minikube-installer and execute the installer.
Start the Minikube
Use vmware as the hypervisor driver
minikube start --driver=vmware
Example output
The first time we start Minikube, we download the VM boot image.
Windows PowerShell Copyright (C) Microsoft Corporation. All rights reserved. PS C:\Users\myuser> minikube start --driver=vmware * minikube v1.9.1 on Microsoft Windows 10 Enterprise 10.0.17134 Build 17134 * Using the vmware driver based on user configuration * Downloading VM boot image ... > minikube-v1.9.0.iso.sha256: 65 B / 65 B [--------------] 100.00% ? p/s 0s > minikube-v1.9.0.iso: 174.93 MiB / 174.93 MiB [ 100.00% 1.36 MiB p/s 2m10s * Starting control plane node m01 in cluster minikube * Downloading Kubernetes v1.18.0 preload ... > preloaded-images-k8s-v2-v1.18.0-docker-overlay2-amd64.tar.lz4: 542.91 MiB * Creating vmware VM (CPUs=2, Memory=4000MB, Disk=20000MB) ... * Preparing Kubernetes v1.18.0 on Docker 19.03.8 ... * Enabling addons: default-storageclass, storage-provisioner * Done! kubectl is now configured to use "minikube" PS C:\Users\myuser>
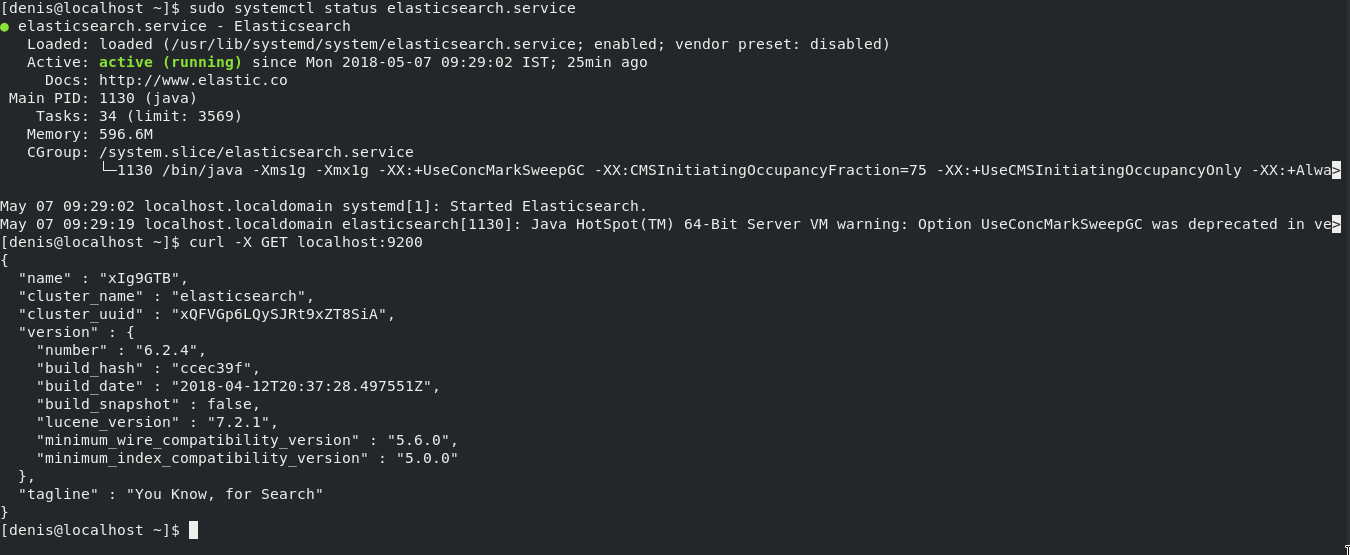
Verify that the Kubernetes cluster is running
Check the Minikube’s status.
Windows PowerShell Copyright (C) Microsoft Corporation. All rights reserved. PS C:\Users\myuser> minikube status m01 host: Running kubelet: Running apiserver: Running kubeconfig: Configured PS C:\Users\myuser>
Get the kubectl cluster info.
PS C:\Users\myuser> kubectl cluster-info Kubernetes master is running at https://192.168.150.129:8443 KubeDNS is running at https://192.168.150.129:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'. PS C:\Users\myuser>
Minikube Start up and Clean Up
Here, we have an example Minikube start (with the VM boot image already installed), followed by stop and delete.
PS C:\Users\myuser> minikube start --driver=vmware * minikube v1.9.1 on Microsoft Windows 10 Enterprise 10.0.17134 Build 17134 * Using the vmware driver based on user configuration * Starting control plane node m01 in cluster minikube * Creating vmware VM (CPUs=2, Memory=4000MB, Disk=20000MB) ... * Preparing Kubernetes v1.18.0 on Docker 19.03.8 ... * Enabling addons: default-storageclass, storage-provisioner * Done! kubectl is now configured to use "minikube" PS C:\Users\myuser> minikube stop * Stopping "minikube" in vmware ... * Node "m01" stopped. PS C:\Users\myuser> minikube delete * Deleting "minikube" in vmware ... * Removed all traces of the "minikube" cluster. PS C:\Users\myuser>